
{kind=link}
{kind=link}
{kind=link}
生活垃圾热值计算模型研究进展*
[王丹1, 2 , 李旭清1, 2 , 杨万勤1, 2, †  ]
]
]
|
|


作者简介:王 丹(1990-),女,博士,讲师,主要从事固体废弃物管理、生态规划方向的研究。杨万勤(1969-),男,博士,教授,主要从事土壤生态及修复、城市生态安全方向的研究。
垃圾热值是决定垃圾是否能采用焚烧处理,以及焚烧处理厂设计和运行的重要因素。经验模型是常用的获取热值的方法。梳理了国内外关于生活垃圾热值计算模型的研究,从热值的表示、计算模型的类型、建模方法、数据来源及样本大小等方面进行综述,发现热值表示方式在该研究领域不统一,建立模型的样本量小,缺乏普适模型,推广难,人工神经网络模型还有待开发。建立精度高、适用性广的普适模型将是未来研究重点。
Heating value (HV) of municipal solid waste (MSW) is an important factor in deciding whether MSW can be treated by incinerate, and also an important factor in determining the design and operation of incineration plants. Empirical models are usually used to estimate the HV of MSW. In this work, the research on HV estimating models of MSW at home and abroad were summarized, and the representation of HV, accuracy of models, methods to build HV models, data sizes and sources were systematically reviewed and compared. The results showed as follows: the representations of HV were inconsistent; the sample size of model was small; there was lack of generalized model which can be applied internationally, and the application of artificial neural networks needs further exploration. Building generalized HV estimating model with good performance which can be applied worldwide might be hot point of future research.
全球生活垃圾年产量已超过20亿t, 预测在2050年将超34亿t[1]。2020年, 我国生活垃圾清运量已达2.35亿t(图1)(数据来源于国家统计局2004-2021年中国统计年鉴, http://www.stats.gov.cn/)。不当的垃圾管理会造成严重的环境污染[2]。同时, 垃圾中蕴含丰富的物质资源和能源[3, 4]。垃圾焚烧处理具有减量化、安全化、快速稳定化、用水少、周期短、易操作、可处理的垃圾种类丰富、占地面积小等优点[5, 6, 7, 8, 9, 10], 是可持续生活垃圾管理中不可缺少的部分[9, 11, 12], 已成为我国垃圾处理的主流方式(图1)。目前, 我国垃圾焚烧发电装机规模、发电量均居世界第一[13], 焚烧厂日处理能力达719 550 t, 发电功率达12 386 988.9 kW, 主要分布在东部地区(图2)[14]。
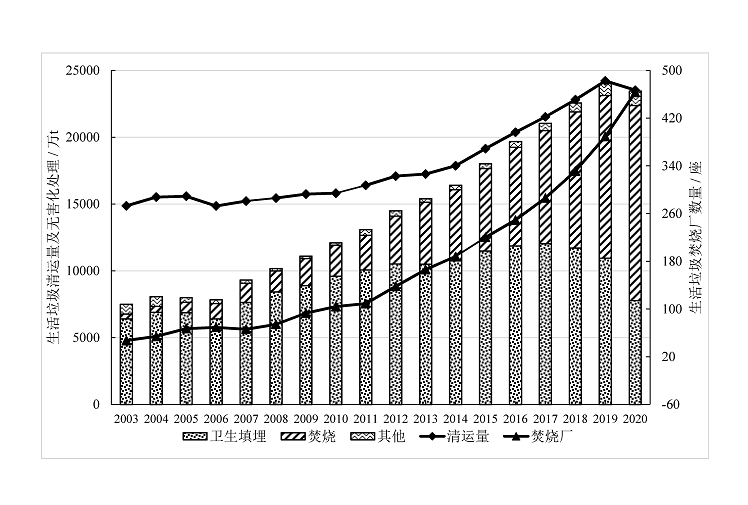 | 图1 2003-2020年我国生活垃圾清运量、无害化处理量及焚烧厂数量(数据来源于国家统计局2004-2021年的中国统计年鉴)Fig. 1 Quantity of collected and safely treated municipal solid waste, and the number of waste incineration plants in China during 2003-2020 (from China Statistical Yearbook 2004-2021) |
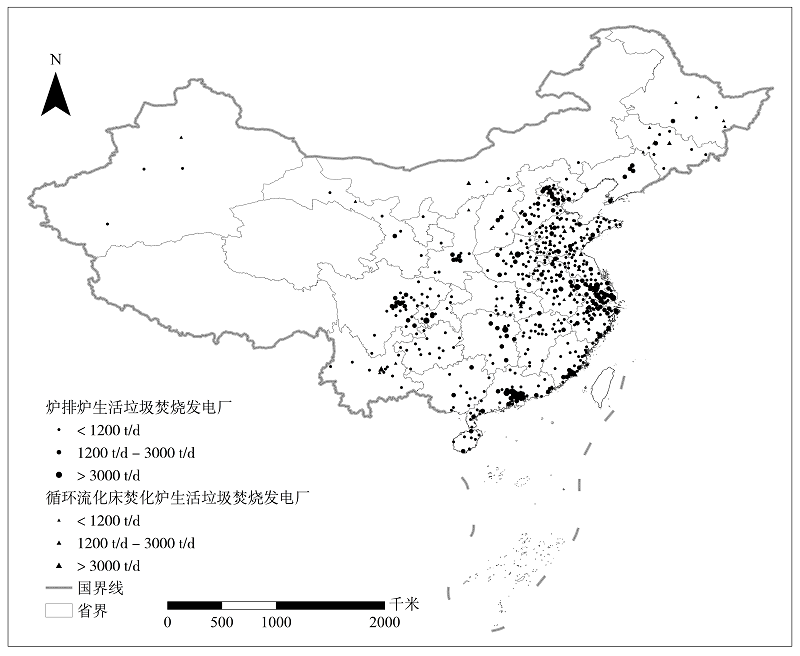 | 图2 我国生活垃圾焚烧厂分布图(数据来源于生活垃圾焚烧发电厂自动监测数据公开平台, https://ljgk.envsc.cn/)Fig. 2 Spatial distribution of MSW incineration plants in China (from Automatic Monitoring Data Disclosure Platform for Municipal Solid Waste Incineration Power Plants, https://ljgk.envsc.cn/) |
目前国内垃圾焚烧发电工艺有机械炉排炉、流化床、回转窑和热解4种类型[15]。机械炉排炉应用最广(图2)[14], 可以处理热值范围宽的生活垃圾, 对预处理的要求不高, 运行及维护简便, 国产化程度高, 投资成本适中[15]。流化床应用较少, 一般用于中小型城市的焚烧厂, 该工艺成本较低且可使垃圾燃烧充分, 但对入炉垃圾要求极高, 需要加入煤炭助燃, 且容易造成空气污染[16]。回转窑焚烧炉燃烧适应性好, 运行稳定, 但占地面积大, 热效率低, 一般用于小规模特种垃圾如医疗废物、工业废物的处置[17]。热解工艺技术先进、可靠, 但对垃圾含水率有一定要求, 对干燥段控制要求较高, 不能满足大型垃圾焚烧厂的要求, 目前还未应用于生活垃圾焚烧, 但在西部人口稀疏、位置偏远地区具有一定应用优势[18]。
垃圾能否采取焚烧处理以及焚烧厂的设计和运行取决于垃圾的热值[19, 20]。热值影响处理技术的选择、辅助燃料的添加及用量、焚烧厂的运行维护、运营管理及经济效益[21, 22]。热值可通过量热仪测定或模型计算。模型计算方便快捷、经济实惠[23], 可用于计算历史垃圾热值[24]。模型研究可以为精确计算垃圾热值及其可持续管理提供科学依据。
热值通常表示为高位热值(higher heating value, HHV)或低位热值(lower heating value, LHV)。高位热值表示单位质量垃圾完全燃烧后, 所有产物冷却到标准状态(298 K, 1 atm), 水以液态形式存在时所释放的热量[25, 26]。低位热值指完全燃烧后产物在150℃, 水以气态形式存在且其中热量未被利用时释放的热量[26, 27]。根据《生活垃圾采样和分析方法》(CJ-T313-2009), 高位热值、低位热值可通过式(1)~ 式(3)进行转化。
${{Q}_{\text{(h)}}}=\frac{1}{m}\sum\limits_{j=1}^{m}{{{{{Q}'}}_{j(\text{h})}}\times \frac{100-{{C}_{(\text{W})}}}{100}}$ (1)
${H}'=\sum\limits_{i=1}^{n}{\left( {{{{H}'}}_{i}}\times \frac{{{{{C}'}}_{j}}}{100} \right)}$ (2)
${{Q}_{(\text{l})}}={{Q}_{(\text{h})}}-24.4\times \left( {{C}_{(\text{W})}}+9{H}'\times \frac{100-{{C}_{(\text{W})}}}{100} \right)$ (3)
式中:${{{Q}'}_{j\text{(h})}}$为干基高位热值, kJ/kg; ${{Q}_{(\text{h})}}$为湿基高位热值, kJ/kg; ${{Q}_{(\text{l})}}$为湿基低位热值, kJ/kg; ${H}'$为干基氢元素含量, %; ${{C}_{(\text{W})}}$为样品含水率, %; ${{{C}'}_{i}}$为某成分干基含量, %; j为重复测定序数; m为重复测定次数; i为各成分序数; n为成分数量; 24.4为水的凝缩热常数, kJ/kg。
热值的表示形式、基准和单位在不同研究中不同。有些甚至未说明是高位热值还是低位热值[28]。热值的表示基准包括湿基[29]、干基[5]、风干基[30]等, 部分研究并未指出采用的基准[4, 5]。热值的常用单位有kJ/kg[31, 32]、kcal/kg[33, 34]、Btu/lb[35]和MJ/kg[10, 36]。这些差异主要是研究目的和使用的采样和分析标准不同导致。国际上常用的生活垃圾采样和分析标准是美国材料实验协会(American Society of Testing Materials, ASTM)(https://www.astm.org/)的系列标准, 如ASTM D5468-02。我国采用的是由中华人民共和国住房和城乡建设部发布的《生活垃圾采样和分析方法》(CJ-T313-2009)和《生活垃圾化学特性通用检测方法》(CJ-T96-2013)。上述这些差异增加了不同研究之间和不同地区之间比较的难度, 可能对后续的研究和应用产生一定的影响。
基于元素含量分析的生活垃圾热值计算模型从杜龙公式演变而来[37], 使用元素含量作为参数[5](见表1)。碳、氢、氧三种元素含量对热值具有明显影响, 因而包含在绝大多数模型中。其他元素如硫、氮、氯也被包含在一些模型中。极少数模型被简化到只包含了一种(例如C)或两种(例如C、H)元素。由于生活垃圾的地域差异性较大, 这类简化模型的使用范围可能会受到限制。
| 表1 基于元素含量分析的生活垃圾热值计算模型 Table 1 Summary of heating value predictive models for MSW based on ultimate analysis |
元素含量分析模型精度通常较高, 但模型精度评价指标及方法各不相同, 对比较难。理论上, 水分对热值产生负影响, 但其系数在一些模型中为正[37]; 硫元素氧化过程为放热反应, 但其系数在一些模型中为负[25, 34, 42, 46]。元素分析通常耗时耗力(4 ~ 5 d), 对实验设备和操作人员要求高[47]。另外, 用于元素分析的样品质量是毫克级, 但生活垃圾性质复杂, 样品的代表性存在争议[29]。
工业特性分析模型以生活垃圾含水率、挥发分和固定碳为参数[13, 48], 见表2。基于R2和MAPE的评价结果, 这类模型精度较元素含量分析模型低。进行工业特性分析的样本质量为克级, 但代表性依然存在问题[29, 31]。工业特性分析同样耗时(4 ~ 5 d)耗力, 对操作人员技术要求较高。因此, 这类模型较少。
| 表2 基于工业特性分析的生活垃圾热值计算模型 Table 2 Summary of heating value predictive models for MSW based on proximate analysis |
物理组成分析模型以生活垃圾可燃物理成分(纸、塑料、木竹、食物等)及水分为模型参数[31], 见表3, 少数模型也将不可燃成分作为参数[49]。纸、塑料、食物三类在生活垃圾中占比大, 是绝大多数模型的参数, 部分模型简化为只包含这三种参数[20, 35]。也有少数模型使用生活垃圾拟组分, 如纤维素、木质素、聚乙烯等作为模型参数[50]。
生活垃圾物理组成分析方法简单, 操作便捷, 对操作人员要求较低[19, 31, 36], 因此, 这类模型数量较多[51], 但精度参差不齐。一般而言, 塑料热值高, 模型中系数应当大于其他成分, 但在部分模型中其系数小于纸类[20, 34, 51], 甚至为负数[10, 32], 这不符合其化学性质; 可能是由于物理组成分析模型只将生活垃圾的大类作为参数, 但同一类垃圾热值幅度较大, 例如, 塑料为17.8 MJ/kg ~ 47.5 MJ/kg, 纸类为10.4 MJ/kg ~ 27.3 MJ/kg[5]。生活垃圾的物理成分和热值易受到环境(地理位置、气候、季节等)[58, 59, 60]、社会经济(工业发展、经济发展、生活水平等)[61, 62, 63]及垃圾管理方式等因素的影响[64, 65, 66, 67]。因此, 物理组成分析模型具有较强的地域性、季节性和时效性。
| 表3 基于物理成分分析的生活垃圾热值计算模型 Table 3 Summary of heating value predictive models for MSW based on physical composition analysis |
多元线性回归分析是最常用的建模方法, 是一种确定因变量${{Y}_{i\left( 1\le i\le n \right)}}$与一个或多个自变量${{X}_{j\left( 1\le j\le n \right)}}$间关系的统计方法[70], 变量间的控制方程为:
${{Y}_{i\left( 1\le i\le n \right)}}=\sum\limits_{j=1}^{m}{{{a}_{j}}{{X}_{j}}}+{{b}_{i\left( 1\le i\le n \right)}}$ (4)
其中:m为自变量个数; n为因变量个数; ${{a}_{j\left( 1\le j\le m \right)}}$为回归系数; b为常数系数。多元线性回归分析具有模型参数可解释、易使用、所有参数都可进行统计检测以及给予预测置信区间等优点[71]。但该方法只包含统计显著、有限数量的参数[72]。然而, 生活垃圾成分复杂、时空差异大, 该方法在建立高精度普适模型上有一定缺陷。
人工神经网络具有较强的容错性、学习性、自适应性、快速信息处理能力和非线性映射能力[49]。其结构如图3所示。目前, 人工神经网络模型基本采用三层结构(表4)。研究表明, 模型精度随变量和样本量增加而提高。因此, 人工神经网络理论上可将生活垃圾所有成分作为参数进行建模。
 | 图3 人工神经网络结构示意图Fig. 3 Structure of artificial neural network |
| 表4 生活垃圾热值人工神经网络模型 Table 4 Summary of heating value predictive models for MSW built by using artificial neural network |
人工神经网络模型较数学模型精度高。但人工神经网络相当于一个黑匣子, 计算过程和结果不能用燃烧的化学机理进行验证[20], 不能计算出标准化系数和变量的系数[72]。并且, 网络结构和参数设置尚没有标准的方法来确定, 参数的设置和调试受研究者经验和时间限制, 建模者需具有一定编程背景[78]。另外, 受数据量和复杂度限制[78], 人工神经网络常用的交叉验证并未应用于生活垃圾热值模型验证。
越来越多研究表明, 生活垃圾热值与理化成分的关系并不一定是线性[32, 45]。随着社会、经济的发展, 生活垃圾成分愈加复杂, 简单的线性模型可能无法精确计算热值, 研究生活垃圾理化成分与热值的非线性关系是必要的。
数据收集一直是生活垃圾热值模型研究中的难点。一方面由于技术和资金缺乏, 另一方面是由于数据访问受限。生活垃圾样品采集费时费力, 样本量通常较小, 容易造成模型过度拟合, 尤其是人工神经网络模型。因此, 部分研究收集文献中精度较低的数据建模[20], 但可能影响模型精度。从表1 ~ 表3可以看出, 模型精度, 尤其是普适模型精度还有待提高。
由于生活垃圾的复杂性和地域性, 目前还没有适用于全球生活垃圾热值计算的普适模型。KHAN等[35]收集35个国家86个城市的数据建立了物理组成分析模型(表3), 但研究中的热值由杜龙公式算得, 且模型建于30年前, 已经不适用于当下生活垃圾热值的计算。WANG等[20]收集了11个国家44个城市1990-2015年间的数据建立了物理组成分析模型(表3、表4), 但精度较低, 且大部分数据来源于亚洲发展中国家。因此, 普适模型精度有待提高。提高精度的可能方案有:(1)对相同来源的生活垃圾建模, 研究表明生活垃圾热值和其来源有很高的相关性[32]; (2)对相似发展水平(如人均GDP等)或经济模式(如工业型城市、服务型城市等)的城市建模, 研究表明工业增加值较高的城市生活垃圾热值相对较高[52]; (3)针对相似自然环境的城市建立模型。
生活垃圾热值计算模型的研究中存在着热值报告基准、单位等不统一, 模型普适性较低、推广难, 数据精度低、样本量小等问题。未来热值研究应加强各地区相关研究领域的合作, 提高生活垃圾热值计算模型的精度, 加强普适模型的研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|